
[42Seoul] get_next_line
0. 과제 설명
파일에서 한 줄씩 읽어오는 함수 get_next_line을 구현한다.
1. fd(File Descriptor)
File Descriptor
- 파일을 대표하기 위해 시스템으로부터 할당 받은 음수가 아닌 정수
- 각각의 프로세스에서 열린 파일의 목록을 관리하는 테이블의 인덱스
흔히 유닉스 시스템에 존재하는 모든 것은 파일이라고 한다. 유닉스 시스템에서는 프로세스가 파일들에 접근할 때 ‘파일 디스크립터’라는 개념을 사용한다.
기본적으로 할당되는 파일 디스크립터
- 0 : 표준 입력(Standard Input)
- 1 : 표준 출력 (Standard Output)
- 2 : 표준 에러(Standard Error)
우리가 파일을 열어서 할당되는 파일 디스크립터들은 3번부터 차례대로 부여받는다.
예를 들어, example.out 이라는 실행파일에서 open() 함수로 “file.txt” 파일을 연다면, file.txt는 fd 3번을 부여 받는다.
#include <fcntl.h>
int main()
{
int fd1;
int fd2;
fd1 = open("file.txt", O_RDONLY);
//file.txt 파일을 첫 번째로 열었으므로 fd1 값은 3이 된다.
fd2 = open("file2.txt", O_RDONLY);
//file2.txt 파일을 두 번째로 열었으므로 fd2 값은 3 다음 값인 4가 된다.
}
File Descriptor의 작동 방식
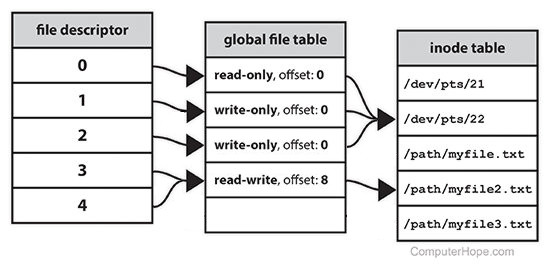
fd는 프로세스가 가지고 있는 fd table의 인덱스이다. fd = 3인 경우, 위 그림처럼 fd table의 3번째 인덱스로 접근하고, 해당 인덱스가 가리키는 inode table로 가서 파일에 접근해 원하는 행동을 할 수 있는 것이다.
file table의 각 칸들은 mode와 inode table pointer의 offset을 가지고 있다.
inode table은 소유자 그룹, 접근 모드(읽기, 쓰기, 실행 권한), 파일 형태, 고유 번호(inode number) 등 해당 파일에 관한 정보를 가지고 있다.
inode란 무엇일까?
파일을 기술하는 디스크 상의 데이터 구조로써 파일의 데이터 블록이 디스크 상의 어느 주소에 위치하고 있는가와 같은 파일에 대한 중요한 정보를 갖고 있다. 각각의 inode들은 고유 번호(inode number)를 가지고 있어서 파일을 식별할 때 사용한다.
터미널에서 ls -i 옵션으로 inode number를 확인할 수 있다.
2. File Control을 위한 함수들
open()
Linux, Unix 계열의 시스템에서 Process가 File을 열 때 open 함수 혹은 openat 함수를 사용할 수 있다.
#include <fcntl.h> // open 함수가 있는 헤더파일이다.
int open(const char *pathname, int flag);
int open(const char *pathname, int flag, mode_t mode);
int openat(int dirfd, const char *pathname, int flag);
int openat(int dirfd, const char *pathname, int flag, mode_t mode);
File Descriptor(fd)값을 반환한다. 에러가 나면 -1을 반환한다.
creat()
새로운 파일 생성은 creat 함수를 이용할 수 있다.
#include <fcntl.h>
int creat(const char *path, mode_t mode)
creat 함수의 단점은 write 모드로만 열린다는 것이다. 다시 읽기 위해서는 creat 함수로 만든 파일을 close 함수로 닫고, O_RDONLY로 읽는 과정이 필요하다.
close()
open 함수로 연 파일은 close 함수로 닫을 수 있다.
#include <unistd.h>
int close(int fd);
정상적으로 종료되면 0, 실패하면 -1을 리턴한다.
read()
file을 열고 난 후 데이터를 읽어올 때에는 read 함수를 사용한다.
#include <unistd.h>
ssize_t read(int fd, void *buff, size_t nbytes);
read 함수는 파일로 부터 읽은 데이터를 저장할 공간인 buff를 가리키는 포인터와, 읽을 데이터의 크기를 받아서 정상적으로 종료되면 읽어온 바이트 수를, 실패하면 -1을, 읽을 데이터가 없으면 (파일의 끝에서 시도) 0을 반환한다.
write()
파일을 열고 난 후 데이터를 쓸 때에는 write 함수를 사용한다.
#include <unistd.h>
ssize_t write(int fd, const void *buff, size_t nbytes);
정상적으로 종료되면 기록한 바이트 수를, 실패하면 -1을 반환한다.
3. static 변수
static 변수란?
static 변수는 전역 변수, 지역 변수 어느 것으로도 이용이 가능하다.
전역이든 지역이든 static 변수는 Data Segment에 위치한다.
외부 정적 변수
전역으로 선언된 static 변수는 외부 정적 변수라고도 불리며, 별도의 초기화 구문이 없어도 0으로 초기화된다.
→ Data Segment의 BSS 영역에 위치하여 0으로 초기화된다. 초기화 구문 존재 시에는 Data Segment의 Data 영역에 위치한다.
내부 정적 변수
특정 함수나 클래스 내부에 선언된 static 지역 변수는 내부 정적 변수라고도 불리며, 외부 정적 변수와 마찬가지로 별도의 초기화 구문이 없어도 0으로 초기화 된다. 또한 내부 정적 변수의 경우에도 프로세스의 메모리가 할당되는 프로그램의 시작 시점에 이뤄지기 때문에 함수 실행 등의 코드 실행으로는 초기화가 이뤄지지 않고 무시된다.
초기화 시점이 프로그램의 시작이라서 함수 실행 시 초기화 구문에서 초기화가 안된다고 했는데, 이렇게 되어도 문제가 없는 이유는 static 변수가 함수 혹은 클래스에 대해서 내부 정적 변수로 이용되는 경우에 각 함수 별 혹은 클래스 별로 공유되는 일종의 공유 변수로 이용되기 때문이다.
#include <stdio.h>
void plus_one()
{
static int num = 1;
printf("%d\n", num);
++num;
}
int main()
{
plus_one();
plus_one();
plus_one();
return (0);
}
위 코드의 경우 static int num이라는 내부 정적 변수의 초기화는 프로그램의 시작에 이뤄지며 초기 값은 1이 된다. 이 때 static int num은 increase_num이라는 함수의 지역 변수처럼 보여 Stack에 위치할 것 같지만, 실제로는 (이 경우에는 초기화 구문이 존재하므로 BSS 영역이 아닌) Data 영역에 위치하고 있다. 위에서 언급했던 초기화 구문이 동작하지 않는다는 얘기는 increase_num 함수 내의 초기화 구문인 static int num = 1이 매 함수 실행마다 이뤄지지 않는다는 말이다. 또한 내부 정적 변수는 특정 함수 혹은 클래스 간 공유되어 사용된다고 했기 때문에 위 main 함수의 실행 결과는 1, 2, 3이 된다.
⚠️ 다른 소스 파일에 존재하는 전역 static 변수 (외부 정적 변수)는 참조할 수 없다.
4. 주의할 점
- 버퍼 한 번 읽을 때 \n\n\n 처럼 개행이 여러번 올 때를 생각하자.
NULL과 안에\0이 들어있는 포인터와는 전혀 다르다. NULL 포인터는 값에 접근하면 segv가 뜬다.- 파일을 읽어서 ‘문자열’로 리턴하는 것이기 때문에, 마지막에 null character terminating을 해줘야 한다.
- 리턴할 것이 아니면 free는 웬만하면 malloc한 곳에서 용도가 끝나면 바로 해주는 것이 베스트.
bonus part
- 연결리스트에서 head는 따로 있는 노드가 아니라, 첫번째 노드를 가리키는 포인터다.
- read가 -1을 리턴했을 때, 모든 노드를 삭제하는 것이 아니라 해당 노드만 삭제해야 한다. 만약 사용자가 실수로 잘못된 fd를 입력했을 때, 기존의 정상 노드까지 다 삭제되어 버리면 남아있던 buf가 사라져서 정보를 잃게 된다. 이렇게 작동하면 사용자가 너무 불편할 것이다. 코드를 짤 때 사용자의 입장에서 생각해보자.
- read가 0을 리턴했을 때는 buf에 남아있는 내용을 리턴해주고 노드를 clear한다.
- node 구조체에 buf_size를 넣어 놓음으로써 ret을 제외한 임시 문자열(buf)의 마지막에
\0문자를 넣을 필요가 없었다. buf_size를 참고하여 문자열을 순회할 수 있었다. 구조체를 만들 때, 해당 구조체에 필요한 정보가 무엇이 있는지 생각해보고 구조체에 추가해서 코드를 간편하게 줄이자.
Leave a comment